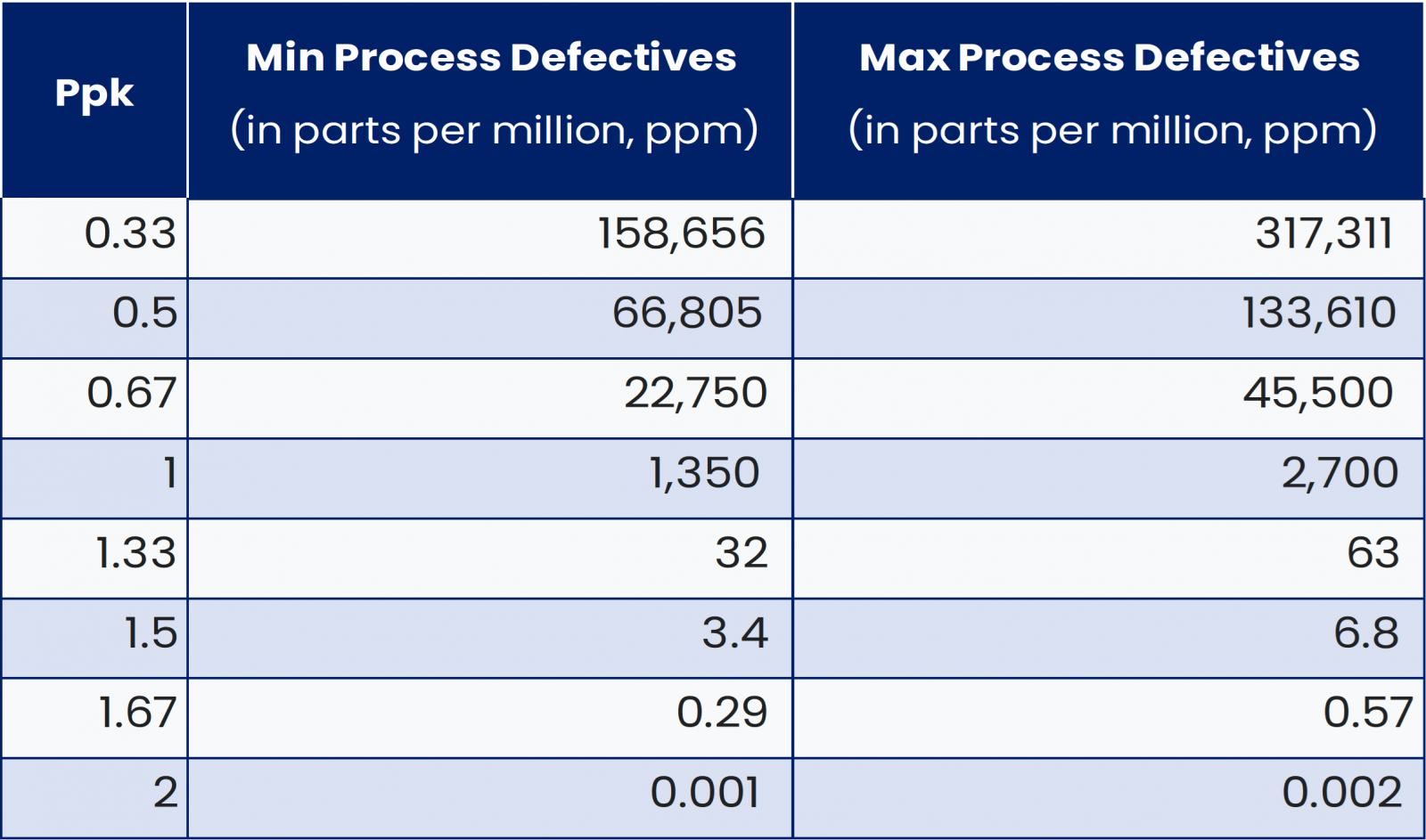
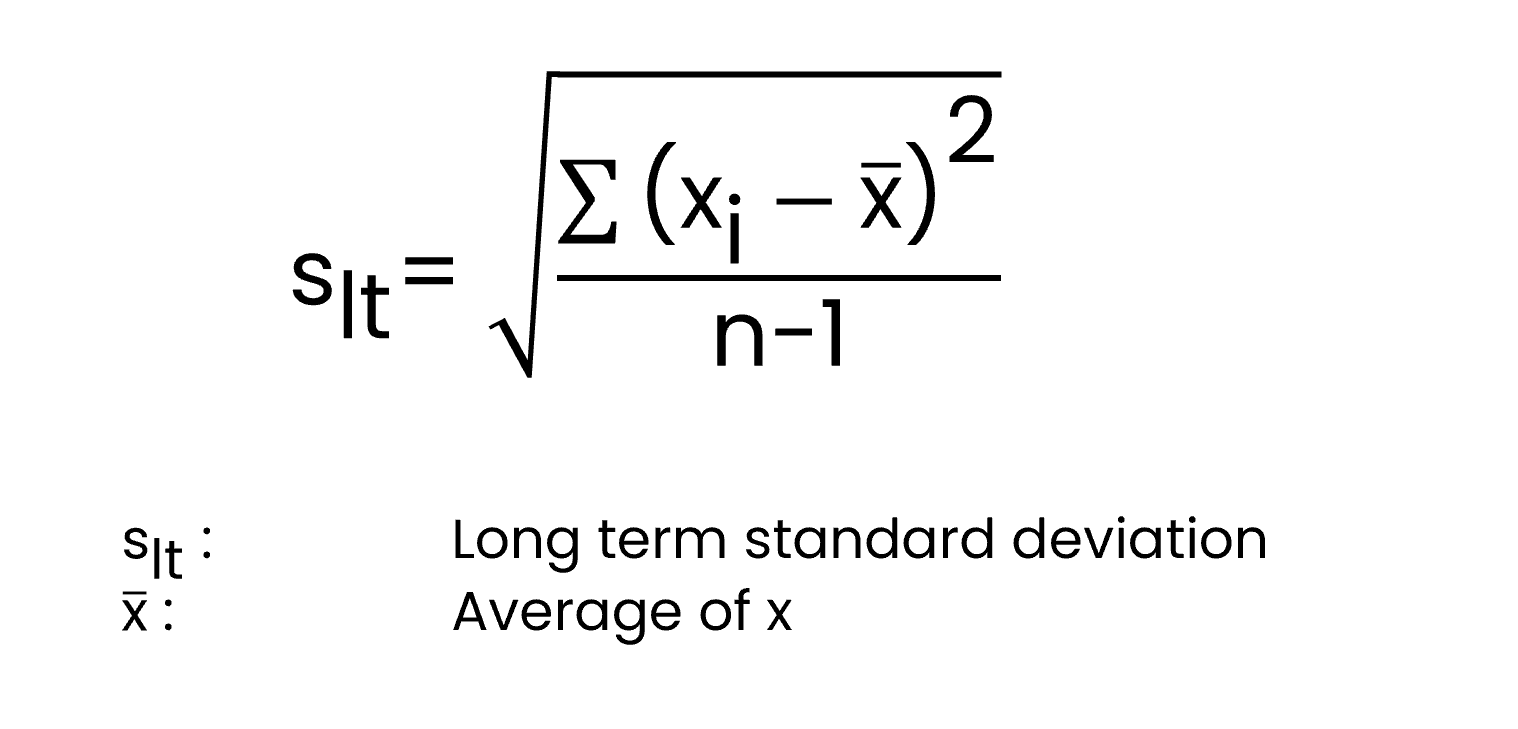-
Courses
- Courses
- Data visualization
- Improve process capability
- Prevent Human Error
- GREEN BELT WITH LEAN FOCUS
- LEAN SIX SIGMA GREEN BELT
- OPTIMIZE VISION SYSTEMS
- METHODS FOR EFFECTIVE LEADERSHIP
- Practical Data Analysis
- Coaching For Lean Six Sigma
- Improving Indirect Processes
- World class Business Processes
- Lean Implementation Expert
- Lean metrics
- Must Knows for effective Calibration
- Systematic problem solving
- Lean Six Sigma Champion
- Lean Champion
- Cost Reduction
- Scrap Reduction
- Basic Statistics
- DMAIC
- Overall Equipment Effectiveness
- Lead time
- Process Mapping
- Process Stability
- Poka Yoke
- Systematic Problem Solving
- Value and Waste
- Custom courses
- Events
- How To
- Contact us
- Log in

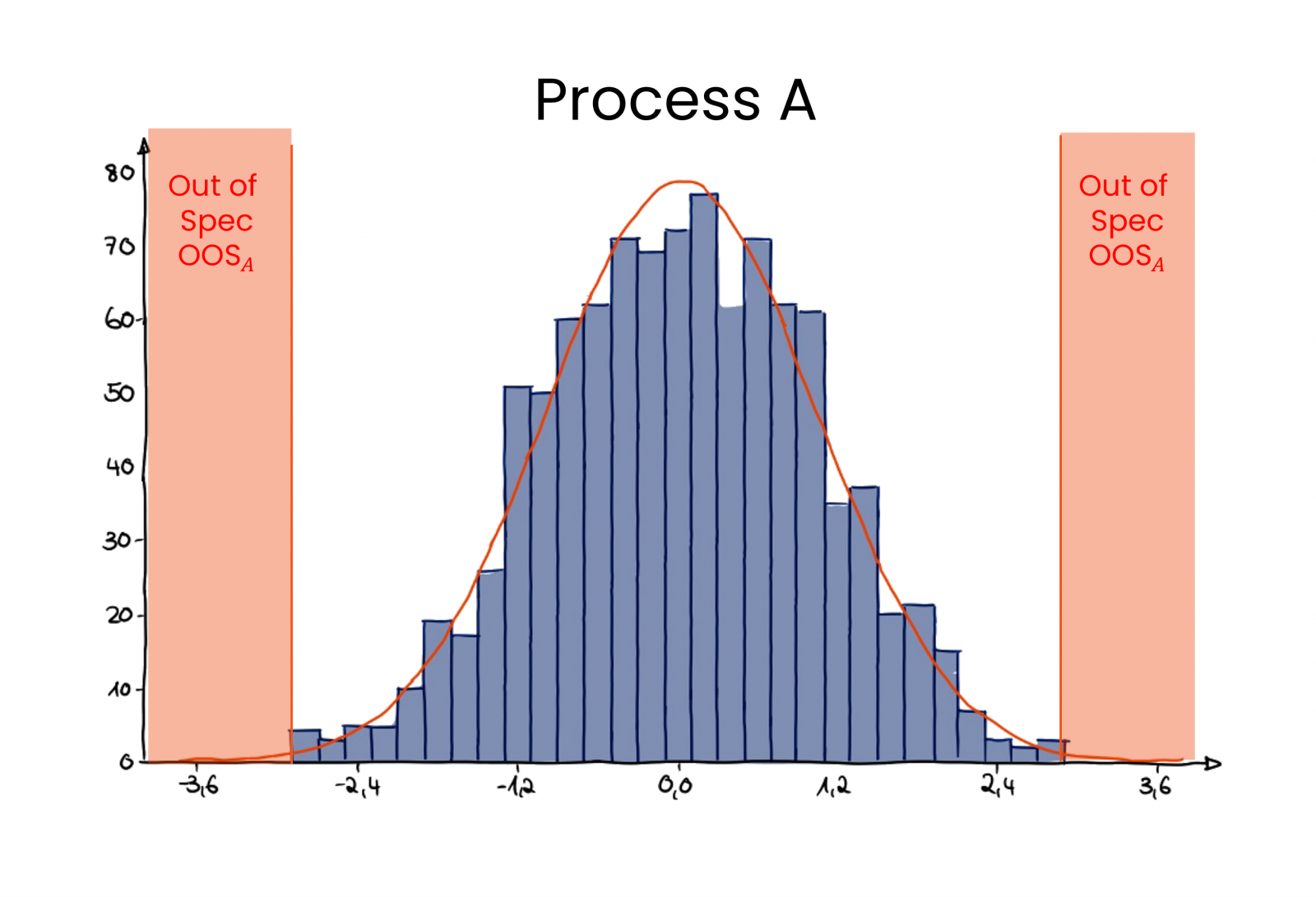
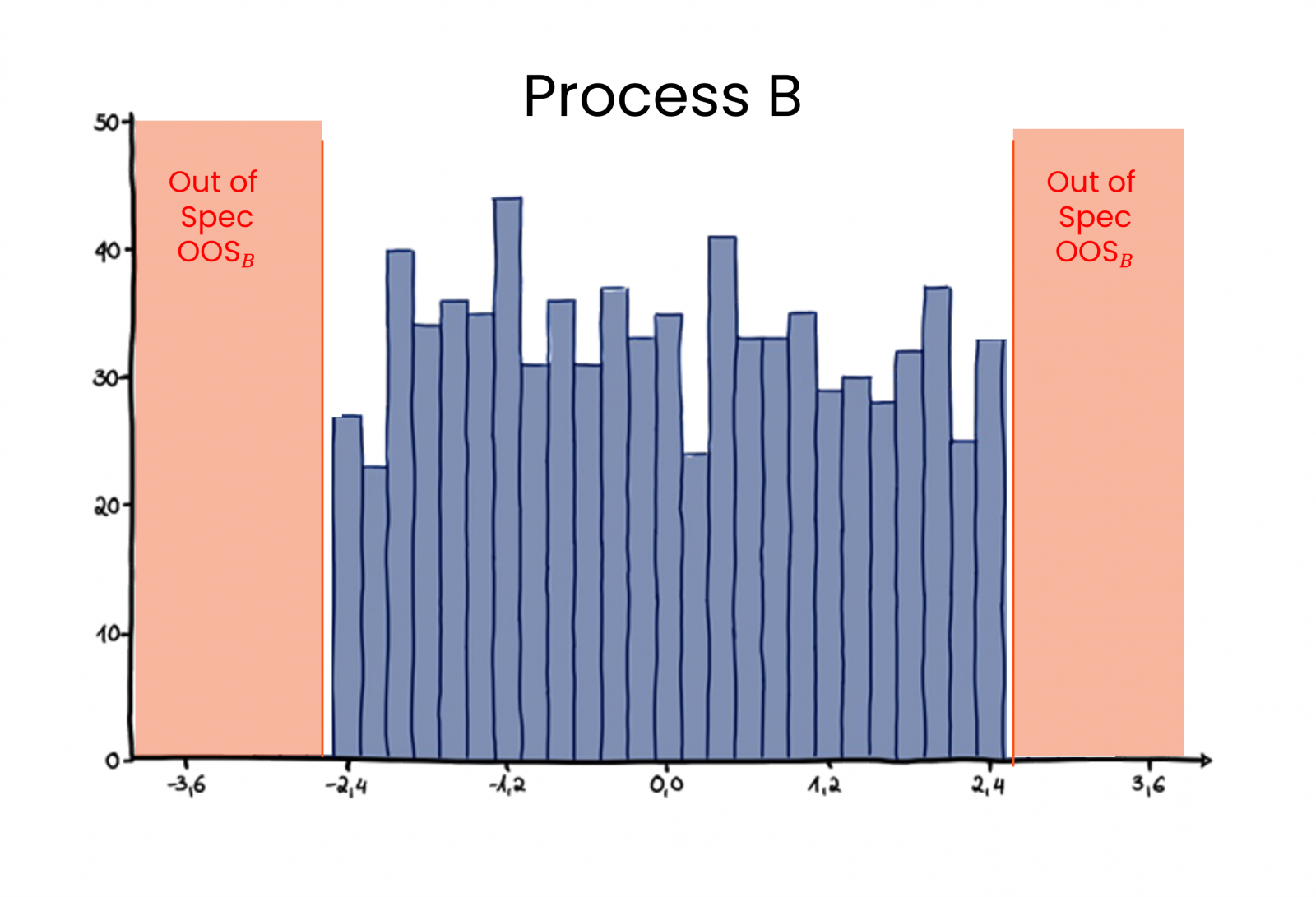
.png)
.png)